|
|
Essentials of Biostatistics Indian Pediatrics 2001; 38: 741-756 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
12. Multiple Measurements and Their Simultaneous Consideration |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
From the Division
of Biostatistics and Medical Informatics, University College of Medical
Sciences Dilshad Garden, Delhi 110 095, India and *Institute of Cytology
and Preventive Oncology, Maulana Azad Medical College Campus., Bahadur
Shah Jafar Marg, New Delhi 110 002, India. An example of multiple measurements such as body fat, weight, height and triceps skinfold thickness in children was discussed in the context of multiple regression setup in the previous Article (1) of this series. That relationship was between one dependent variable (y) and a set of independent variables (xs). How to proceed if there were more than one dependent variable? For example, thyroid function is evaluated by simultaneous consideration of T3, T4 and TSH. These might be related to age, diet, exercise, stress, etc. Here we have a set of three dependent variables - the three thyroid parameters. The classical multiple regression discussed earlier has only one dependent variable. Simulta-neous consideration of many dependent variables requires multivariate methods. Let us further clarify the distinction between a multivariate setup and a univariate setup. In the univariate multiple regression situation also the number of variables or measurements is more than one. However, only one is dependent and the others are independent or regressors. If we are able to find how pulse rate depends on body temperature and diastolic blood pressure (DBP) level in children with pyrexia of unknown origin using a multiple regression, then the question it is supposed to answer is: What pulse rate is expected in a child with temperature 101°F and DBP 60 mmHg? Thus the regressors are considered fixed and known in this situation. Only the response y, which is pulse rate in our example, is considered to be subject to sampling fluctuation. Although regression can be used in a cross-sectional study where both y and xs are simultaneously observed (and thus both are subject to fluctuation), it is interpreted as if xs were fixed. Since only one variable y is considered stochastic(2), the regression of the previous Article is essentially a univariate technique though the data are multivariate. For a genuine multivariate setup, it is essential that there are several stochastic variables. The second essential requirement for a valid multivariate setup is that these stochastic variables are interrelated. Physical growth of infants is assessed by measurements that include weight (y1), length (y2), and head circumference (y3). These are interrelated. Maternal weight (x1), maternal height (x2), breastfeeding (x3), infec-tions (x4) could be among the determinants of infant growth. If the ys are not interrelated, analyses using univariate technique for weight, length, and head circumference can be separately done. But conclusions so arrived at would be valid separately for weight, height, and head circumference but not jointly for growth. The reasons for this are: (a) every univariate conclusion is subject to defined chance of Type I error such as 0.05 when based on statistical test of hypothesis. Individual conclusions combined together would have much higher chance of error than specified threshold 0.05. This situation is same as that of multiple comparison discussed earlier (3); (b) individual univariate analyses ignore the correlated nature of the measure-ments in case they are correlated. Special methods are required that ensure that the total probability of Type I error remains within the limit and due consideration is given to the correlation structure. Multivariate methods take care of both these problems. Multivariate analysis is an intricate process. We are trying to explain it in simple terms. Our objective in this Article is only to apprise you of the situations where these methods could and should be used. The kind of conclusions that can be reached by such methods is discussed. This could help you to consult a statistician when needed. The statistical tests of significance in a multivariate setup are based on a criterion such as Wilks L or Pillais trace. These are analogous to the F-test in a univariate setup. The details of the multivariate test criteria are not given in this Article. Computer packages are available for analysis. It is important that the correct method is used for the problem in hand. Computer packages still are not given that kind of intelligence. Thus, a proper discretion is required while using computer packages. Consider a multivariate situation such as thyroid functions (T3, T4 and TSH) being investigated for their dependence on age, protein intake and body mass index. The objective is to find the form of dependence. A type of analysis called multivariate multiple regression is needed for this setup in which there is a set of dependent quantitative variables and a set of independent quantitative variables. In another situation if dependents are quantitative and independents are quali-tative then the method used is multivariate analysis of variance (MANOVA). Investiga-tion of dependence of thyroid functions on gender and degree of malnutrition is an example of MANOVA setup. As mentioned later, this really amounts to finding that the average values of different thyroid functions is same in the two genders and in different grades of malnutrition. These two techniques are discussed in Section 12.1. When the set of dependents is qualitative then the technique called multivariate logistic regression is used. We do not discuss this technique in this Article. Consider another situation. Suppose different measurements of maternal nutrition are available for different clinical groups of nutrition status in newborn children. A rule is required for discriminating among the groups so that any newborn could be assigned to the most appropriate malnutrition or healthy group on the basis of maternal nutrition measurements. This type of setup is called discriminant analysis. This is discussed in Section 12.2. Another multivariate situation arises when there is no distinction such as dependent or independent among measurements. For example, this can arise when the subjects are to be divided into clinical entities on the basis of signs-symptoms and measurements. The interest is to search for a correlation structure among subjects or among variables that can explain the observations. Such a problem can be addressed by the techniques of cluster analysis and factor analysis. These are discussed in Section 12.3. Some investigations involve long series of measurements made at successive points of time. For example, monthly pediatric admis-sions of various diseases such as poliomyelitis, diarrhea, respiratory infection, etc., constitute a long series for a period, say, of last 72 months. These longitudinal measurements also correlate with one-another. Analysis involving such measurements is called time series analysis. This is discussed in Section 12.4. In Section 12.5 we give some concluding remarks for this series that ends with this Article. You might be able to note after reading this Article that multivariate methods are not easy to adopt nor easy to interpret. That explains their limited use. Another limitation of these methods is that they require intricate calculations. It is sometimes a challenge to choose a correct computer programme. We advise you to use these methods only in consultation with an expert biostatistician.
Hypertension is defined in terms of both systolic and diastolic blood pressure. It can be considered to depend on family history, dietary pattern, obesity, smoking, stress, etc. Thus, there is a dependent set and there is an independent set of measurements. Another example of this setup is: various globulins (alpha1, alpha2, beta and gamma) considered to depend on serum vitamin A, plasma pH and serum iron levels. The independent set may contain only one variable but the dependent must be more than one for a valid multivariate setup. As usual, the methods for studying the relationship between these two sets of variables depend on whether the variables are qualitative or quantitative. These are discussed below in brief to create awareness of the utility of techniques. For further details, see Indrayan and Sarmukaddam(4). Multivariate Multiple Regression Consider heart rate, respiratory rate and oxygen saturation of a group of neonates investigated for dependence on gestational age, birth weight and bilirubin level. Thus, there are three dependent and three inde-pendent variables in this case. This is a multivariate setup in which both the sets are quantitative. The form of relationship between these two sets can be obtained by multivariate multiple regression. So far as the regression equations are concerned, univariate regression for each dependent variable and multivariate multiple regression look alike. The regression coefficients in both the setups would be same. If the objective is only to obtain regression equations, there is no need for a multivariate method. However, for statistical significance, multivariate methods should be used. We explain this with the help of an example. Example 1: Consider dependence of neonatal measurements such as birth weight (BWt), skinfold thickness (ST), babys mid arm circumference (BMAC), total body fat (TFat) and ponderal index (PInd) on maternal anthropometry such as height (Ht), weight (Wt), mid arm circumference (MAC) and triceps skinfold thickness (TST). There are five neonatal measurements in the dependent set and four maternal measurements in the independent set. We use data (unpublished) on these measurements for a random sample of 1000 subjects for univariate and multivariate analysis. The same regression equations are found for univariate as for multivariate setup. Multivariate test of significance (based on Wilks L) is obtained by using a statistical software for five neonatal measurements investigated to depend on four maternal measurements. The values of L are not shown to avoid complexity. We do not present univariate results here but they indicate that some neonatal measure-ments are affected by maternal anthropometry and some are not. Valid conclusion about the effect of each maternal parameter on the neonatal parameters combined is obtained by the multivariate results. Ht does not have a statistically significant (P = 0.328) influence on the neonatal measurements, but the other three maternal parameters, viz., TST (P = 0.011), Wt (P <0.001) and MAC (P <0.001) have a significant influence. Such a composite conclusion has less than 5% overall chance of being wrong. The multivariate method allows a conclusion on the basis of joint Type I error for all five indicators of neonatal parameters together. MANOVA In an earlier Article(3), we used ANOVA in the case of one quantitative dependent and one or more qualitative independent. The example discussed was on heart rate and grades of anemia. When we have more than one quantitative dependent variable, the technique used is multivariate ANOVA (MANOVA). For example, the dependent hematinic measurements could be hematocrit, hemoglobin and mean corpuscular volume values in children. The independent could be age and gender groups. Gender is qualitative anyway and age becomes qualitative when divided, e.g., as <5, 5-10, 10+ years. The primary purpose of MANOVA would be to test the equality of means of hematinic parameters in children of two genders and different age groups. Interaction of age and gender can also be investigated. In place of different hematinic parmeters, suppose we have mortality indicators such as neonatal mortality rate (NMR) and post-neonatal mortality rate (PNMR) for different countries in different years. The countries are divided into two groups, namely, with and without vitamin A intervention at population level. Since measurements are made several times on each country, solution for this is provided by MANOVA for repeated measures. The following is an example of classical MANOVA. Example 2: Suppose we have birth weight (BWt), length (L), head circumference (HC) and mid arm circumference (MAC) of neo-nates as dependent variables and pregnancy interval (PInt), gestational age (Gest) and parity (Par) as independent variables. The independent variables are converted into categories for the purpose of this illustration on MANOVA. PInt is divided into categories: 0, 1, 2 and 3+ years; Gest into three cate-gories: <28 weeks; 29-42 weeks and >42 weeks; and Par into three categories: 0, 1 and 2+. Now this is a valid setup for MANOVA. The results obtained from these data using a computer package are discussed below. The analysis for each neonatal parameter individually (univariate) and together (multi-variate) are performed but the values of test criterion not shown here. In the univariate ANOVA, PInt significantly influences BWt (P = 0.028) and L (P = 0.004) but not HC (P = 0.082) and BMAC (P = 0.551). MANOVA results show that the neonatal parameters are not significantly affected by PInt, since P turns out to be 0.08 for PInt, which is more than significance level 0.05. The results of uni-variate and multivariate ANOVA for different Gest groups and Par groups incidentally coin-cide in this case. The conclusion is changed in the case of PInt from the univariate to the multivariate setup. The correct conclusion on the combination of neonatal measurements is obtained by the multivariate test. The MANOVA and multivariate multiple regression tests are based on a multivariate Gaussian pattern of the observations. Using the methods described in an earlier Article(3) each variable can be checked separately for a Gaussian pattern. If individual variables are approximately Gaussian, there is a great likelihood that they jointly too are multivariate Gaussian. 12.2 Discriminant Analysis Suppose we want to predict the survival or nonsurvival of neonates affected by hemolytic disease with the help of x1 = cord hemoglobin (Hb) and x2 = bilirubin (BI) concentration measurements. These are J = 2 measurements. The procedure to find the linear combinations of variables that best separate the groups is called discriminant analysis. The linear functions so obtained are called discriminant functions. These functions are considered optimal when they minimize the chances of wrong prediction. If there are K groups, the number of discriminant functions required is (K 1). If there are two groups, only one discriminant function is needed. These are of the type Dk = b0k + b1k x1 + ... + bJk xJ , k = 1, 2, ... , (K 1) [1] Computer package can be used to obtain this complex function. If J measurements x1, x2, ... , xJ are available for each subject, it is not necessary to use all J of them. Stepwise procedure similar to the one explained for classical multiple regression(1) can be used to select simple discriminant functions with fewer variables. These are preferable, provided they have adequate discriminating power (see the following). When values of x1, x2, ... , xJ are substituted in function [1], the obtained value of Dk is called the discriminant score. This is illustrated below in the example of survivors of hemolytic disease, using Hb and BI values in the discriminant function for various children. The discriminant score helps to predict the survival (or nonsurvival). The prediction would sometimes match with the actual survival and sometimes not. The actual and predicted outcome can be classified in a 2 ´ 2 contingency table. This is used to find the percentage correctly classified, called the discriminating power. For the discriminant analysis to be successful, this power should be high, say exceeding 80%. Despite high power, it is desirable that the discriminant functions are externally validated on a new set of subjects before recommending them for use for prediction. Example 3: Armitage and Berry(5) reported a discriminant function D = 0.6541(Hb) 0.3978(Bl) for survival or nonsurvival. This is based on 79 infants affected by hemolytic disease. Mean Hb and Bl levels for survivors are 13.897 g/100 ml and 3.090 mg/100 ml, and for nonsurvivors 7.756 g/100 ml and 4.831 mg/100 ml, respectively. The pooled means of Hb and Bl for all patients combined are 10.827 g/100 ml and 3.961 mg/100 ml, respectively. Substitution of these means in the above discriminant function gives D = 5.506. This is used as critical value for classifying the subjects as survivors and nonsurvivors. A value of D >5.506 would indicate that the child is likely to survive in the sense that the chance is more than 50%. Else the child is not likely to survive. Discriminant score for each new neonate of hemolytic disease can be obtained by substituting his Hb and Bl values in the discriminant function. For example, for a child with Hb level of 8.7 and Bl of 3.4, the discriminant score is D = 0.6541 ´ 8.7 0.3978 ´ 3.4 = 4.338. This is less than 5.506. Thus, this child with hemolytic disease has less than 50% chance to survive. In this example, out of 79 children, 68 (86.1%) were found to be correct-ly classified by the discriminant function.
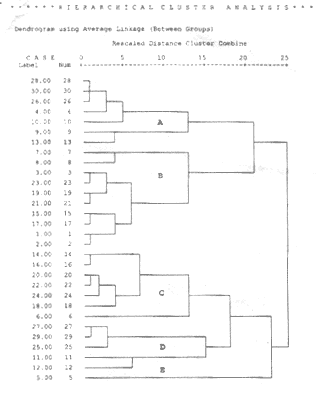
When no distinction such as dependent and independent is present among variables, it might be of interest to study their structural relationships. Based on a large number of health related variables, suppose we want to divide a group of children into two or more groups such that children within each group have similar health. One group may comprise children in poor health, second group children with moderate health and third group children with good health. The number of groups is not predetermined, and there is no dependent variable in this case. For example, children with diarrheal dehydration may be grouped into different grades of dehydration based on weight loss, urinary output, fall in blood pressure and rise in heart rate. A group of children with similar levels in such variables are put together into one "cluster". Such a method is called cluster analysis. Each cluster of similar children for diarrheal dehydration can possibly be managed with same regimen, whereas children with different level of dehydration may require a different regimen. Suppose we have multiple measurements on a group of school children such as exami-nation scores in different subjects, physical anthropometry and socioeconomic status of the family. The interest might be to study the underlying structure using the interrelations among different variables, called constructs. These constructs are unobservable entities. Each entity may be common to many observa-tions. These are called factors. Such factors can be identified by suitable statistical methods. The example given later may clarify it further. Cluster Analysis You may be interested in the problem of dividing subjects or units into a small but unspecified number of affinity groups. The natural clusters formed are usually mutually exclusive and provide a convenient summary of multiple measurements. A name is subse-quently assigned to these clusters depending on their common features. For example, different enzyme levels can be used to classify the liver diseases such as malignancy, hepatitis and cirrhosis. The proximity between the subjects is assessed on the basis of similarity in a set of measurements. Those with high proximity go into one group and those with low proximity are placed to some other group where proximity is higher. As many groups are formed as needed for internal homogeneity and external isolation of groups. Several methods of cluster analysis are available. A commonly used algorithm(7-9) is described below. Hierarchical Agglomerative Algorithm: This is the most commonly used algorithm for clustering the units. It proceeds sequentially from the stage in which each subject is considered to be a single member "cluster". At each stage, the number of groups is reduced by one, by clubbing the two groups found most similar to each other. This process goes on stage by stage. In the final stage there is a single group containing all units. The method is called hierarchical agglomeration as the clusters are obtained by joining the clusters from the previous stage. There are several methods for defining the intergroup distance or similarity. Names such as single linkage, complete linkage, average linkage and Wards are used for different methods (10). Statistical packages are available to perform computa-tions and to provide dendrogram(6) that depicts the agglomeration at different stages. The number of natural clusters actually present in the data can be decided using a set of criteria. These are not discussed in this Article. For details refer Everitt(10). Cluster analysis can be based on one or more number of variables. For five variables, it is discussed in the example given below. Example 4: Figure 1 shows the dendrogram obtained from a hypothetical data on 30 child-ren with acute bronchiolitis when clustered on the basis of gestational age, respiratory rate, pulse rate, arterial oxygen tension (PaO2) and oxygen saturation (SaO2) by pulse oximetry. This shows that the children with case numbers 28, 30, 26, 4, 10, 9 and 13 are placed together to form group A. Similarly, the groups B, C and D are formed with case numbers 7 through 2, 14 through 6 and 27 through 12 as sequenced in Fig. 1. The child-ren in the respective groups A, B, C and D are generally those who developed no complica-tions and recovered quickly, developed mild complications and recovered after a while, and developed severe complications and recovered very late, and those who could not be saved. Subsequently, the groups A and B merged as one cluster, C and D as another cluster. Child number 5 remained a distinct entity that did not fall into any cluster till very late of agglomeration process. Perhaps this is not a case of bronchiolitis. This example shows that it is possible to divide bronchiolitis patients into recovery categories on the basis of measurements at the time of hospital admission. Thus, medical care can be geared up accordingly.
Factor Analysis The purpose of factor analysis is to describe the covariance relationships among a set of variables. Health in its comprehensive form (physical, social, and mental) can be measured for teen-age children by a host of variables such as kind and severity of complaints if any, obesity, lung functions, smoking, examination scores and parental income. It is not apparent how much of, say, performance in examination scores is ascribable to physical health, how much to each of the other components (social, mental) of health, and how much is the remainder that cannot be assigned to any of these compo-nents. For a variable such as obesity the physical component may be dominant, whereas in examination scores the mental component may be dominant. Physical, social and mental health are unobservable constructs. Factor analysis helps to describe the relation-ship among observed variables in terms of few underlying but unobservable constructs. These are called factors and can be used subse-quently for other inferential purposes. The following example should clarify the meaning and purpose of such analysis. The example is simple with four variables for easy under-standing but in practice generally a large number of variables are used for factor analysis. Example 5: Four child mortality indicators for different States of India are used for illustra-tion. The indicators considered are still birth rate (SBR), neonatal mortality rate (NMR), post-neonatal mortality rate (PNMR) and one-to-four year mortality rate (OTFMR). The data are for the year 1998 and taken from Sample Registration System report(11). The SBR, NMR, and PNMR are directly available and OTFMR is derived from under-5 mortality rate (U5MR) and other indicators. The factor model looks similar to a regression model for each indicator. Instead of regressors and coefficients, factor model has unobservable common factors and loadings. The loadings are the correlations between the common factors and indicators. The estimated values of the common factors are called factor scores. These scores are often used as inputs for subsequent analysis. We use them later to rank different States of India with respect to magnitude of child mortality. Factor analysis is done on the above four indicators for 16 States of India as units. These indicators for different States are shown in Table I. The factor analysis revealed that first factor explained 63.9% of the total variation in the four mortality indicators and the second factor explained another 26.4%. The two together explained 90.3% of the total variation in the four mortality indicators. The loadings for the first factor are 0.922, 0.923, 0.905 and -0.045; and for second factor 0.149, -0.062, -0.279, and 0.992, respectively for the indicators NMR, PNMR, OTFMR and SBR. The indicators having high loadings for a particular factor represent strong correlation between the factor and the indicators, and thus can be grouped together. Indicators of mortality after birth, namely, NMR, PNMR and OTFMR are identified as factor-1 and indicator of mortality before birth, namely SBR, is identified as factor-2 in this example, considering the values of the loadings. TABLE
I Data on Four Indicators Along with Factor Scores for
Different
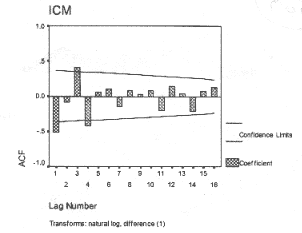
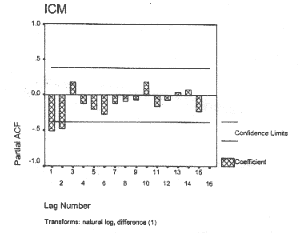
The following are some situations where this type of analysis is used: (a) To reduce the dimensionality, i.e., many indicators can be transformed to a few factors, say 2 or 3 or 4. In our example, four indicators are represented by two factors. In real sense, a large number of indicators can be represented by a few factors. In many situations, such reduction in dimen-sionality is considered a step forward in understanding the data. In our example, child mortality has two main factors - those causing death before birth and those causing death after birth; (b) It is possible to identify natural groups of indicators through the interrelations of a set of variables. In our example, NMR, PNMR and OTFMR are identified as one set of indicators and SBR is identified as another; (c) The factor scores of the identified factors can be used for subsequent analysis. For example, a composite index(12) can be computed using the factor scores. Table I shows that the States of the country can be ranked as per the index of child mortality (ICM) that we have computed by combining factor scores. This index measures the magnitude of child mortaltiy. For details of such an index see Satynarayana et al.(13). Statistical packages such as SYSTAT and SPSS can be used for computations required for factor analysis. 12.4 Time Series Analysis Measurements made at different points of time are related with one-another and thus can be considered as multivariate measurements. Time series is a collection of observations made sequentially in time. For example, monthly pediatric admissions to the emer-gency ward for a period of, say, 10 years is a long time series comprising 120 points. Special feature of time series is the fact that successive observations usually are not inde-pendent. Therefore, the analysis must take into account the time order of the observations. When successive observations are dependent, future values may be predicted from past observations. The other important objectives of time series analysis are description and explanation. For example it may be possible to use the variation in one time series to explain the variation in the other series when obser-vations are taken on two or more related variables. Descriptive features The first step in the time series analysis generally is to plot the data versus time as a line diagram and to obtain simple descriptive measures of the main properties of the series such as various types of variation and trend. A brief account of some descriptive features is as follows. Variations: With the help of plots of observations against time, various variations in a time series can be studied. These can be seasonal, cyclical, and other fluctuations. Many series of hospital admissions of infectious diseases exhibit seasonal variation. Asthma cases in a hospital show a peak in every first quarter of the calendar year. Diarrhea is typically high in summer or rainy months. In such a series you may want to measure seasonal effect and eliminate it before further study is made on seculasr trend. The cyclical variation is frequently observed in a series of economic data and but rarely in medical data. However, cholera in Bengal from 1850 to 1950 had a cyclic feature. Trend Determination: For example, trend can be studied in the monthly series of incidence of tuberculosis or of degenerative diseases. Trend is defined as the long-term change in the mean level. For determining trend, the simple linear regression discussed in previous Article(1) can be used by taking the measure-ment variable, say, IMR (let us denote it by Zt , t =1, 2, 3, ... , T) as dependent on time. The slope coefficient in the regression can be used to describe the trend if it is linear. The basic difference between regression analysis and time series analysis is that in the regression analysis we regress Zt on t, treating Zt as dependent at various points of time, whereas in the time series analysis, we regress Zt on its previous value Zt 1 and make best use of sequencing in the series. Time series modelling Suppose we have a series of index of child mortality (ICM)(12) values for the State of Assam for the years 1970 to 1998 (Table II). Observations in the time series (say, Z1, Z2, ... , ZT) are usually serially correlated. This serial correlation (also called autocorrelation) is extremely used in the time series modelling. The autocorrelation is the product moment correlation between actual series and the lagged series. The lagged series is the same as the original series but is put one year later as shown in Table II. This is shown after taking logarithm in our example. Logarithm is taken to stabilize variance. In addition to the autocorrelations (AC), partial autocorrelations (PAC) can also be computed for different lags. The concept of partial correlation explained in the previous Article(1) can be used to understand partial AC. The plot of sample autocorrelation coefficients against different lags is called autocorrelation (AC) plot and the similar plot for partial autocorrelations is called PAC plot. These plots on a stationary time series are useful for identifying the appropriate model. Stationarity assumption(14) is a central feature in the development of time series models. This assumption includes the condi-tions such as: (a) constant mean and variance in the series over time, and (b) the serial covariance or autocovariance independent of historical time. To make our Assam ICM series stationary, (a) we use logarithmic trans-formation of ICM series (as indicated by the values in the footnote of Table II, (b) take sequential differences of the transformed series to remove the trend. The differenced series (i.e., differences between successive values) is shown in DIFF column of Table II. This first differencing is widely used and is generally sufficient to attain apparent stationarity. This DIFF can now be used for time series modelling since this is stationary. An illustration of AC and PAC plots (or functions) for the first differenced (DIFF) log ICM series given in Table II are shown in Figs. 2 and 3.
The stationary models that are generally used in practice are autoregressive (AR), moving average (MA), and mixed AR and MA called ARMA models. The details of the models(14,15) are not included here because of complexity. A general rule for deciding the type and order of the model using these plots is as follows. If the correlations after lag 1 suddenly declines or vanishes in AC plots then it indicates MA(1) model. If this happens in PAC plots then it indicates AR(1) model. Else the model is ARMA(1,1). Similarly for other lags. Computer program is available for estimation of model parameters in SPSS and SYSTAT. The difference between values observed and values predicted from the model, called residuals, is useful in assessing the goodness of fit of the model. Residual variance, AC and PAC plots of residuals obtained for the fitted model and a chi-square like measure based on ACs of residuals called Ljung-Box statistic(15) can be used for check-ing the adequacy of the fitted model. We discuss these briefly in the context of our ICM series. The AC and PAC plots in Figs. 2 and 3 for DIFF show significant correlations at lags 1, 3, 4 and at lag 1, 2, respectively. The signifi-cance is assessed from the confidence limits shown in figures. After this they suddenly decline. Thus, these plots suggest MA(4) model and AR(2) model for this series. The diagnostic tests such as Ljung-Box statistic and nonsignificant correlations in AC and PAC plots of residuals obtained from this models helped us to say that MA(4) is a better model than AR(2) in this case. The Ljung-Box goodness of fit P value for these two models are 0.51 and 0.016, respectively. The latter value show that AR(2) is not a good fit. In the goodness of fit, values of P greater than 0.05 are considered adequate. The MA (4) model using data up to 1997 gave a forecast of ICM for 1998 as 29.4 as against observed 31.3. This is not a particularly good forecast in this case as the value of ICM takes a turn around from decreasing to increasing trend after the year 1995. Various indicators of child mortality in Assam show an upward trend at this time. This might be due to under-reporting in the preious years and also due to shorter series. Thus time series application is to be done with caution. Remarks: (a) Time series analysis is generally recommended for series with 100 time points or more to obtain a reliable model. In case of series with fewer time points, one proceeds by experience and past information to come up with a preliminary model(14). In the example given above the series is short but this is given just for illustration. (b) Repeated measure-ments such as weight, height, head, arm and chest circumferences, used for growth curves are typically too short series and methods discussed above are not likely to be very useful. Methods described in the previous Article (1) for determining linear and curvi-linear trend by using polynomials of different order are likely to provide reasonable estimate of the average trend in this case. (c) Suppose we have data on two time series and we are interested in examining the extent of relation-ship between them. A tool called cross-correlation (CC) can evaluate this(15). (The AC on the other hand is for the relationship in a single time series between time points.) Suppose daily measurements on average peak expiratory flow rate of school children and environmental pollution levels are available. The two residual series after fitting of appro-priate models can be studied for cross correlations. This will indicate the extent to which the two series are related with one-another. (d) Application of time series techni-que is scanty in medical literature. This is perhaps due to the requirement of a lengthy series and the difficult nature of its analysis.
We stated in the first Article(16) of this series that uncertainties resulting from variations must be recognized. In order to control such uncertainties, various types of studies such as descriptive and analytical are undertaken(17). In medicine, these studies are never done on all subjects of the population but a fraction of subjects called sample is selected. We emphasized(18) the need for a random sample in such studies, as it should represent the target population so that the findings can be extrapolated. Medical uncertainties can be studied only through collection of observations, their collation and analysis. Numerical and graphical methods of summarizing the observations are required to have an insight of the variation in data collected or derived for any study(2,6). These methods basically depend upon the type of data that it is qualitative or quantitative. Next we explained why the reference values in medicine are needed and how are they generally obtained in the face of uncertainties (19). This requires use of a distribution such as Gaussian. The preliminary concepts of probability and validity of diagnostic tests are also discussed in this Article as a means to measure the extent of certainty. The receiving operating curves (ROC) that are based on sensitivity and specificity are not discussed. Mortality and morbidity measures for a group or a community as against an individual are discussed in the next Article(20). Survival is complementary to mortality. The analysis of survival data is not discussed in this series. The basis for quantifying the uncertainties that arise due to sampling process along with the meaning and rationale of confidence intervals and P-values are discussed in the next Article (21). This also includes the procedure for determining the number of subjects required in a sample for it to have some desirable confi-dence. Subsequent articles provide methods of obtaining P-values for qualitative and quantitative types of data in some common situations(3,22). These help in reaching to a reliable conclusion despite variations and uncertainties so commonly present in medical data. Then we discussed methods for assessing relationships in terms of strength, form and agreement(1). The concept of multivariate techniques required for simultaneous con-sideration of several variables is discussed in the present Article. Thus, we have covered many biostatistical methods but a large number still remain uncovered. Only the basics are included in this series. That is the reason that we called it Essentials of Bio-statistics. Our effort was to explain these essentials in a nonmathematical language for our medical colleagues with clear emphasis on medical relevance. Yet at some places the language has become unfriendly. Uncertainties also arise due to poor quality of measurements and statistical fallacies. Actually these are errors that intro-duce bias. If the data are not of good quality, best of statistical tools of analysis can not lead to correct conclusions. For controlling the quality, frequent check on validity and reliability of tools and instruments used for data collection is a must. We have not been able to discuss this aspect in this series. Those interested may see Indrayan and Sarmukuddam(4). Correct compilation and correct analysis of correct data tells us nothing but truth. Fallacies can occur due to inadequate and biased samples, incorrect choice of analysis, inappropriate use of statistical packages, errors in presentation of findings, errors due to misinterpretation, etc. They should not be ascribed to statistical methods. Nevertheless, our advice is not to depend too much on statistical results. Nothing can replace common sense. Depend on your intuition more than science. If scientific methods fail your intuition, look for reasons. They would most likely lie with science than with intuition. Acknowledgements We
are indeed very grateful to Dr. H.P.S. Sachdev, Editor-in-Chief, Indian
Pediatrics, for giving us opportunity to present this series. We are also
thankful to the editor for granting permission to use the material published
in this journal for various illustrations in this series. Thanks to Dr.
Siddharth Ramji and Dr. A.P. Dubey for providing us unpublished data sets
for illustration purposes. Our thanks also to the reviewers who provided
constructive sugges-tions from time to time. We hope that the readers
have found the series useful. Enormous demand for reprints indicates that
this effort has not been fruitless. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| References | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
![]()